Deep learning models, such as neural networks, have become increasingly popular in recent years due to their ability to learn and make predictions from large amounts of data. However, one of the major challenges with these models is that they can be difficult to understand and interpret. This is known as the “black box” problem, as it is often unclear how the model is making its predictions.
Explainability, also known as interpretability, is the ability to understand and interpret the decision-making process of a deep learning model. It is becoming an increasingly important issue as deep learning models are being used in more and more critical applications such as medical diagnosis, self-driving cars, and financial fraud detection.
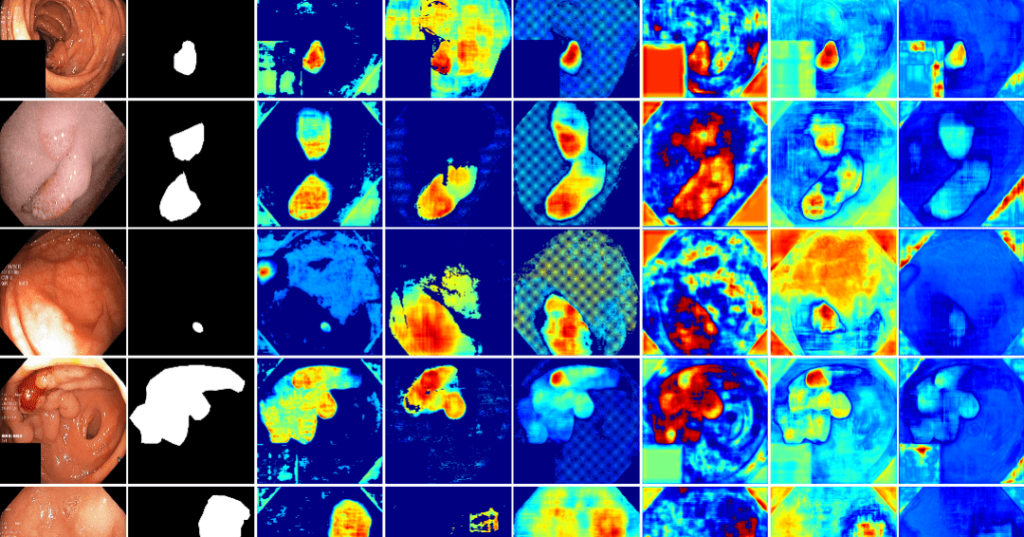
There are several methods that can be used to improve the explainability of deep learning models. One approach is to use simpler models, such as linear models, which are easier to interpret. Another approach is to use visualization techniques, such as saliency maps, which can show which parts of the input data the model is paying attention to when making its predictions.
Another approach is to use model-agnostic methods, which are methods that can be applied to any model regardless of its architecture. One example is LIME (Local Interpretable Model-agnostic Explanations) which generates an interpretable model around the black-box model to understand the local behaviour of the model around a specific input.
Another approach is to use model-specific methods, which are methods that are designed to work with a specific type of model. One example is layer-wise relevance propagation (LRP) which is used to understand the contribution of each feature to the final output.
Lastly, post-hoc methods are methods that are applied after the model has been trained. One example is SHAP (SHapley Additive exPlanations) which assigns each feature an importance score based on its contribution to the final output.
In conclusion, explainability is a crucial aspect of deep learning models, as it allows us to understand and interpret the decision-making process of the model. There are several methods that can be used to improve the explainability of deep learning models, including visualization techniques, model-agnostic methods, model-specific methods and post-hoc methods. With the increasing use of deep learning models in critical applications, it is important to continue researching and developing methods to improve their explainability.