Semantic image segmentation is the process of labeling each pixel of an image with its corresponding class. An encoder-decoder based approach, like U-Net and its variants, is a popular strategy for solving medical image segmentation tasks. To improve the performance of U-Net on various segmentation tasks, we propose a novel architecture called DoubleU-Net,
Architecture
DoubleUNet is a combination of two U-Net architectures stacked on top of each other.
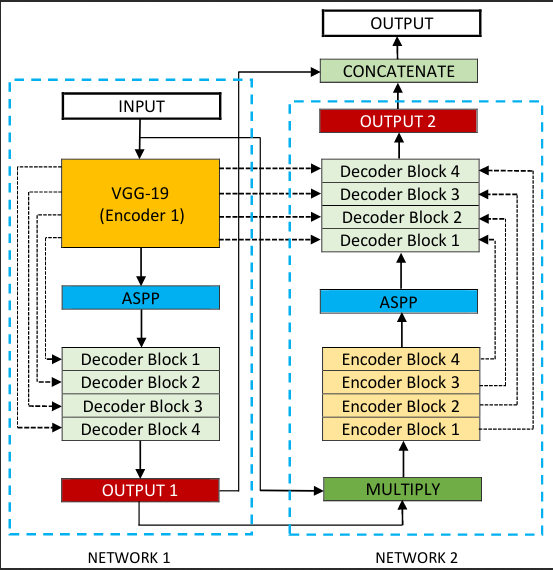
Figure shows an overview of the proposed architecture. As seen from the figure, DoubleU-Net starts with a VGG-19 as encoder sub-network, which is followed by decoder sub-network. What distinguishes DoubleU-Net from U-Net in the first network (NETWORK 1) is the use of VGG-19 marked in yellow, ASPP marked in blue, and decoder block marked in light green. The squeeze-and-excite block is used in the encoder of NETWORK 1 and decoder blocks of NETWORK 1 and NETWORK 2. An element-wise multiplication is performed between the output of NETWORK 1 with the input of the same network. The difference between DoubleU-Net and U-Net in the second network (NETWORK 2) is only the use of ASPP and squeeze-and-excite block. All other components remain the same.
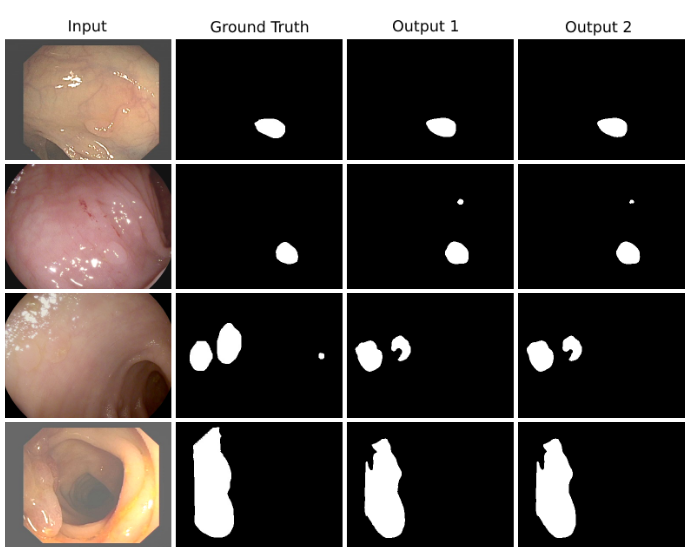
In the NETWORK 1, the input image is fed to the modified U-Net, which generates a predicted mask (Output-1). We then multiply the input image and the produced mask (Output-1), which acts as an input for the second modified U-Net that produces another mask (Output-2). Finally, we concatenate both the masks (Output-1 and Output-2) to see the qualitative difference between the intermediate mask (Output-1) and final predicted mask (Output-2).
We assume that the produced output feature map from NETWORK 1 can still be improved by fetching the input image and its corresponding mask again, and concatenating with Output 2 will produce a better segmentation mask than the previous one. This is the main motivation behind using two U-Net architectures in the proposed architecture. The squeeze-and-excite block in the proposed networks reduces the redundant information and passes the most relevant information. ASPP has been a popular choice for modern segmentation architecture because it helps to extract high-resolution feature maps that lead to superior performance.
Quantitative and qualitative results
We have evaluated DoubleU-Net using four medical segmentation datasets, covering various imaging modalities such as colonoscopy, dermoscopy, and microscopy. Experiments on the 2015 MICCAI sub-challenge on the automatic polyp detection dataset, the CVC-ClinicDB, the 2018 Data Science Bowl challenge, and the Lesion boundary segmentation datasets demonstrate that the DoubleU-Net outperforms U-Net and the baseline models. Moreover, DoubleU-Net produces more accurate segmentation masks, especially in the case of the CVC-ClinicDB and 2015 MICCAI sub-challenge on the automatic polyp detection dataset, which has challenging images such as smaller and flat polyps. These results show an improvement over the existing U-Net model. The encouraging results, produced on various medical image segmentation datasets, show that DoubleU-Net can be used as a strong baseline for both medical image segmentation and cross-dataset evaluation testing to measure the generalizability of deep learning models.
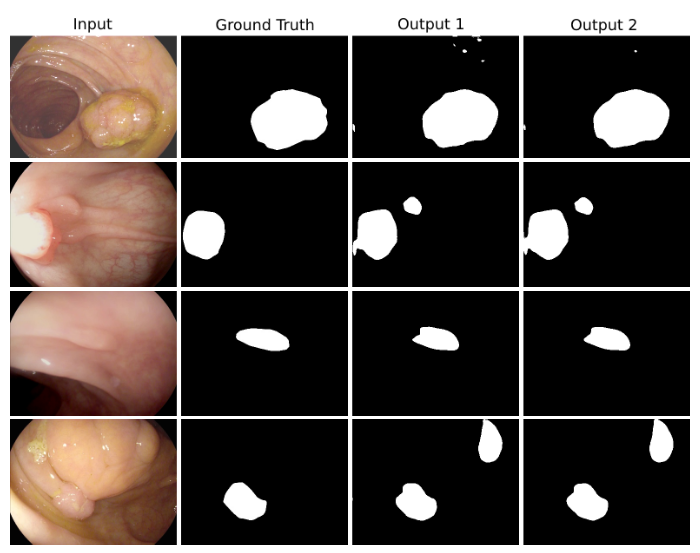
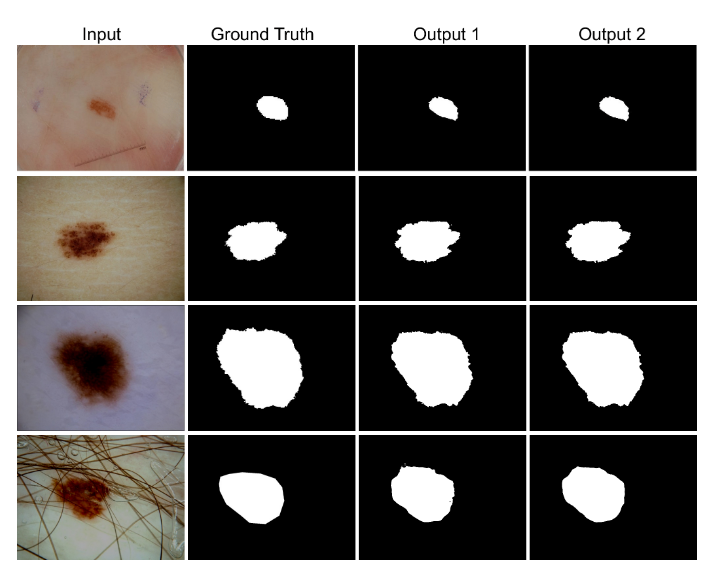
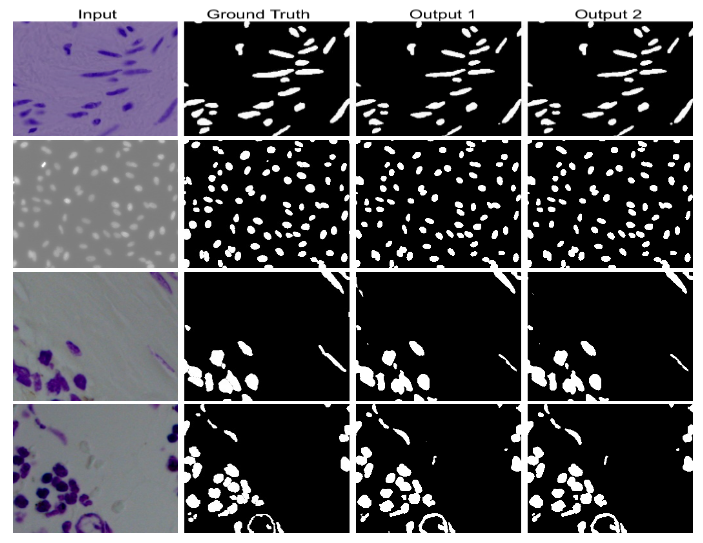
Conclusion:
In this paper, we have proposed a novel CNN architecture called DoubleU-Net. The DoubleU-Net has five main components, namely two U-Net networks, VGG-19, a squeeze-and-excite block and ASPP. The performance of DoubleU-Net is significantly better when compared with the baselines and U-Net on all four datasets.
Moreover, the proposed architecture is flexible, and that makes it possible to integrate other CNN blocks into DoubleU-Net. We believe that the segmentation results can be improved by further integrating different CNN blocks and by the use of post-processing techniques such as conditional random field and Otsu threshold.
References:
Github Link: https://github.com/DebeshJha
Paper Link: https://arxiv.org/pdf/2006.04868.pdf